
颠覆未来:6710 亿参数大模型如何重塑AI世界?——从 ChatGPT 到 DeepSeek 的超级大脑进化论

大模型恐怕是最近最热门的词汇了,从ChatGPT到DeepSeek,一轮比一轮火爆!在人工智能的世界里,大模型就像超级大脑一样,能够理解和处理海量的信息。那么,什么是大模型呢?让我们一起来探索这个神奇的领域。
所谓大模型,是指具有大规模参数和复杂计算结构的机器学习模型。首先是这个“大”字,体现在三个方面:第一是参数量大,第二是计算量大,第三是数据量大。参数量就是模型中含有多少个权重参数(单位一般用Billion 十亿表示)。计算量是指这些权重参数之间有多少次浮点数运算。数据量大,不用多说,很容易理解。如DeepSeek-R1-671B,参数数量6710亿,14.8万亿个token的数据量。
1 大模型发展历程
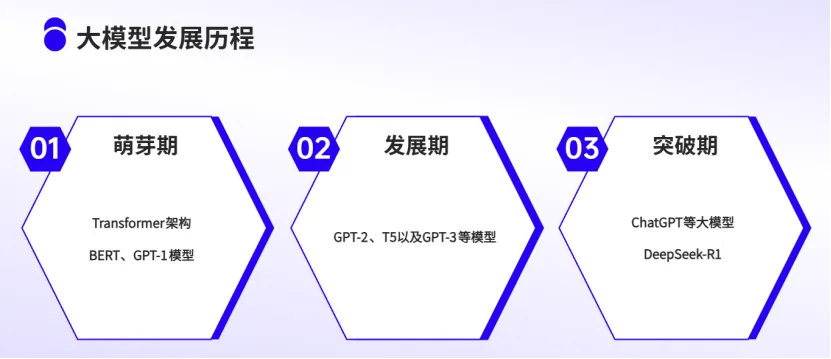
大模型的发展历程可以大致划分为三个阶段:
2017至2018年是基础模型的萌芽期,以Transformer架构的诞生和BERT、GPT-1模型的问世为标志,开启了预训练语言模型的新纪元。
2019至2022年是大模型的发展期,GPT-2、T5以及GPT-3等模型在参数规模以及能力上大幅提升。
2022年起则是大模型的突破期,ChatGPT等大模型的发布标志着AI技术的变革。2025年初,中国初创公司推出的DeepSeek-R1,以卓越的计算效率和资源优化能力震撼了全球科技产业。
2 大模型分类
大模型的分类有很多种方式,可以按照输入数据、模型架构、应用领域等进行划分。例如,根据输入数据类型的不同,大模型分为语言大模型(NLP)、视觉大模型(CV)和多模态大模型。按照应用领域的不同,又分为通用大模型和垂直大模型。
3 大模型是一个系统
大模型实际上是一个庞大而复杂的系统,如果把大模型比作一个完整的人,基础模型就是骨骼,数据是粮食,算力就是各类器官。
大模型=基座模型(骨骼)+数据(粮食)+算力(器官)
绝大多数大模型以Transformer 框架为核心。Transformer模型作为一种先进的自然语言处理模型架构,通过引入自注意力机制实现了高效的并行计算和全局上下文建模。直白来讲,Transformer大模型架构比之前的RNN更好实现了类似人脑的记忆、推理的能力。至于太专业的内容,不细赘述。
数据!数据!数据!重要的事情说3遍。数据是大模型的能量来源,吃得好,吃得饱才有干劲儿,例如DeepSeek训练时需要的14.8万亿个token的数据量。

算力,类似人类的核心器官(心、肺、肌肉等)。提到算力,就得说说GPU(Graphics Processing Unit)。最早它是一种专门用于图像和视频处理的处理器,随着科技的发展,现在GPU已经超出图像成为人工智能的计算利器。选择GPU而非CPU进行大型模型训练主要是因为GPU在并行处理能力、高吞吐量和针对机器学习任务的优化方面的优势,也就一个字,“快”!
4 大模型的应用
大模型的应用主要集中在自然语言处理、计算机视觉、语音识别、推荐系统等方面。我们常说的大模型多数指的是大语言模型。大语言模型可以完成上下文学习、常识推理、数学运算、代码生成等。大语言模型功能很强,需要我们根据个人的需求去发掘。
结语
以上是对大模型的一点浅显认识,希望能够让大家对大模型有个基本认识,AI 时代不懂点大模型好像有点说不过去。我们正在进入并经历一个新的时代,大模型作为最强“大脑”,未来一定会非常容易地被大家获取、接受。未来有太多可能,相信最好的办法是拥抱它。
(作者:北矿科技 鲁恒润)